编程范式
编程范式是:解决编程中的问题的过程中使用到的一种模式,体现在思考问题的方式和代码风格上。这点很像语言,语言本身会体现出不同国家的人的思考方式和行为模式。
常见的编程范式有下面几种:
- 命令式编程
- 面向对象编程
- 函数式编程
除了这三个之外,我们还会接触到其他的编程范式,如:声明式。
编程范式之间不是互斥关系,而是可以结合在一起使用的。我们往往需要结合各种编程范式来完成一个程序功能。
在学习写代码的过程中,我们一般先接触命令式编程,然后学习面向对象编程,面向对象编程可以让我们很方便地处理更复杂的问题。这篇文章里,我们会介绍函数式编程。
不同的编程范式有不同的代码表现

比如从来没有坐过电梯的人,第一次坐电梯,电梯在 10 楼,人在 1 楼,他会按下,让电梯下来。按错按钮是因为他用了祈使语,而不是把自己的想法提交出去。
相似地,你写的代码就像电梯的按钮界面,是让自己或者他人阅读的。只有达成了相同的共识才能更好地理解。通过这次文章可以让大家更好地理解函数式编程。
下面是几种编程范式的代码片段:
const app = 'github';
const greeting = 'Hi, this is ';
console.log(greeting + app);
这是命令式编程,通过调用 const 和 console.log 进行赋值和输出。
const Program = function() {
this.app = 'github';
this.greeting = function() {
console.log('Hi, this is ' + this.app);
};
};
const program = new Program();
program.greeting();
这是面向对象编程,我们把整个程序抽象成现实生活中的一个对象,这个对象会包含属性和方法。通过类的概念,我们有了生成对象的一个工厂。使用 new 关键字创建一个对象,最后调用对象的方法,也能完成刚才我们用命令式编程完成的程序功能。
const greet = function(app) {
return 'Hi, this is ' + app;
};
console.log(greet('github'));
这是简单的函数式编程,通过函数的调用完成程序的功能。但是一般情况下的函数式编程会更复杂一些,会包含函数的组合。
不同的编程范式适用的场景不同
- 命令式编程:流程顺序
- 面向对象编程:物体
- 函数式语言:数据处理
我们往往会在不同场景下使用不同的编程范式,通过编程范式的结合来实现一个程序。
我们通过命令式编程去让程序按步骤地执行操作。
面向对象编程则是把程序抽象成和现实生活中的物体一样的对象,对象上有属性和方法,通过对象之间的修改属性和调用方法来完成程序设计。
而函数式编程则适用于数据运算和处理。
再仔细看下之前的代码,我们就会发现这些编程范式往往是要结合起来使用的。
const app = 'github';
const greeting = 'Hi, this is ';
console.log(greeting + app);
这个例子里面,除了命令式之外,我们还可以把前两句语句赋值解读成声明式编程。
const Program = function(app) {
this.app = app;
this.greeting = function() {
console.log('Hi, this is ' + this.app);
};
};
const program = new Program('github');
program.greeting();
这里例子里面,我们看到在类的 greeting 方法里面也用到了命令式的 console.log。在最后的执行过程中的 program.greeing() 也是命令式的。
const greet = function(app) {
return 'Hi, this is ' + app;
};
console.log(greet('github'));
函数式编程
使用函数式编程可以大大提高代码的可读性。
函数式编程的学习曲线
你编写的每一行代码之后都要有人来维护,这个人可能是你的团队成员,也可能是未来的你。如果代码写的太过复杂,那么无论谁来维护都会对你炫技式的故作聪明的做法倍感压力。
对于复杂计算的场景下,使用函数式编程相比于命令式编程有更好的可读性。
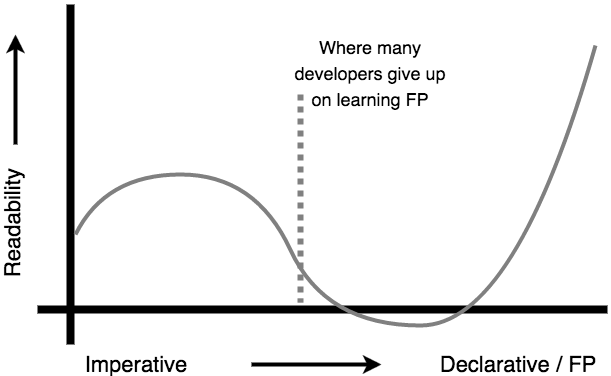
从命令式的编程到函数式编程转换的道路上,可读性会变低,但是一旦度过了一个坎,也就是在你大量使用函数式编程时,可读性便会大大提升。可是我们往往会被这个坎阻挠,在发现可读性下降后放弃学习函数式编程。
因此除了学习函数式编程本身的知识之外,我们还需要明白学习可能经历的过程和最终的结果。
函数式编程定义
函数是第一公民。
JavaScript 是一门在设计之处就完全支持函数式编程的语言,在 JavaScript 里面,函数可以用 function 声明,作为全局变量,也就是这里说的“第一公民”。我们不再使用 var、const 或者 let 等关键字声明函数。我们也会大大减少变量的声明,通过函数的形参来替代变量的声明。
函数式编程大量通过函数的组合进行逻辑处理,因此我们在后面会看到很多辅助函数。通过这些辅助函数,我们可以更方便得修改和组合函数。
什么是函数?
一个函数就是包含输入和输出的方程。数据流方向是从输入到输出。
在数学里面我们学到的函数是这样的:
y = f(x)
在 JavaScript 里面,函数是这样表示的:
function(x) { return y; }
代码中的函数和数学意义上的函数概念是一样的。
函数和程序的区别
- 程序是任意功能的合集,可以没有输入值,可以没有输出值。
- 函数必须有输入值和输出值。
函数适合的场景
函数适合:数学运算。不适合:与真实世界互动。
实际的编程需要修改硬盘等。如果不改变东西,等于什么都没做。也就没办法完成任务了。
JavaScript 和函数式编程
JavaScript 支持函数式编程。使用 JavaScript 进行函数式编程时,我们要使用 JavaScript 的子集。不使用 for 循环, Math.random, Date, 不修改数据,来避免副作用,做到函数式编程。
下面,面向 JavaScript 开发者,介绍在 JavaScript 函数式编程中用到的一些概念。
高阶函数
高阶函数是由一个或多个函数作为输入的函数,或者是输出一个函数的函数。
[1, 2, 3].map(function(item, index, array) {
return item * 2;
});
[1, 2, 3].reduce(function(accumulator, currentValue, currentIndex, array) {
return accumulator + currentValue;
}, 0);
map 和 reduce 是高阶函数,它接收一个函数作为参数。
纯函数
纯函数有两个特点:
- 纯函数是幂等的
- 纯函数没有副作用
纯函数是可靠的,可预测结果。带来了可读性和可维护性。
幂等
幂等是指函数任意多次执行所产生的影响和一次执行的影响相同。函数的输入和输出都需要幂等。
function add(a, b) {
return a + b;
}
上面的函数是幂等的。
function add(a) {
return a + Math.random();
}
上面使用了随机数,每次执行得到的结果不同,所以这个函数不幂等。
var a = 1;
function add(b) {
return a + b;
}
上面使用到函数外部的数据,当外部数据变化时,函数执行的结果不再相同,所以这个函数不幂等。
var c = 1;
function add(a, b) {
c++;
return a + b;
}
上面的函数修改了函数外部的数据,所以也不幂等。
副作用
副作用是当调用函数时,除了返回函数值之外,还对主调用函数产生附加的影响。
最常见的副作用是 I/O(输入/输出)。对于前端来说,用户事件(鼠标、键盘)是 JS 编程者在浏览器中使用的典型的输入,而输出的则是 DOM。如果你使用 Node.js 比较多,你更有可能接触到和输出到文件系统、网络系统和/或者 stdin / stdout(标准输入流/标准输出流)的输入和输出。
纯函数
一个纯函数需要满足下面两个条件:
- 纯函数是幂等的
- 纯函数没有副作用
不可变数据
不可变数据是指保持一个对象状态不变。
值的不可变性并不是不改变值。它是指在程序状态改变时,不直接修改当前数据,而是创建并追踪一个新数据。这使得我们在读代码时更有信心,因为我们限制了状态改变的场景,状态不会在意料之外或不易观察的地方发生改变。
在函数式和非函数式编程中,不可变数据对我们都有帮助。
使用不可变数据的准则
- 使用
const,不使用let - 不使用
splice、pop、push、shift、unshift、reverse以及fill修改数组 - 不修改对象属性或方法
使用不可变数据的弊端
不可变数据有更多内存开销。
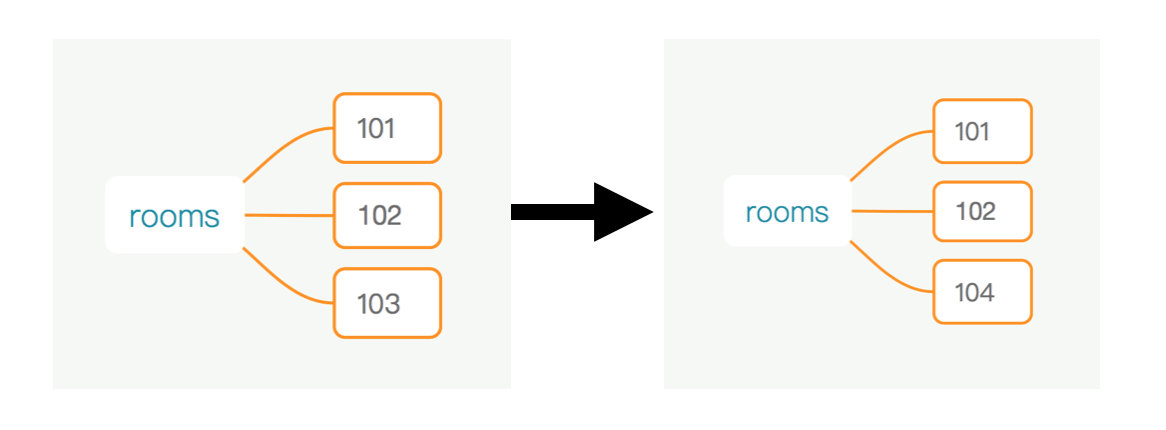
修改数据的情况下,直接替换了变量的值,内存开销不变。
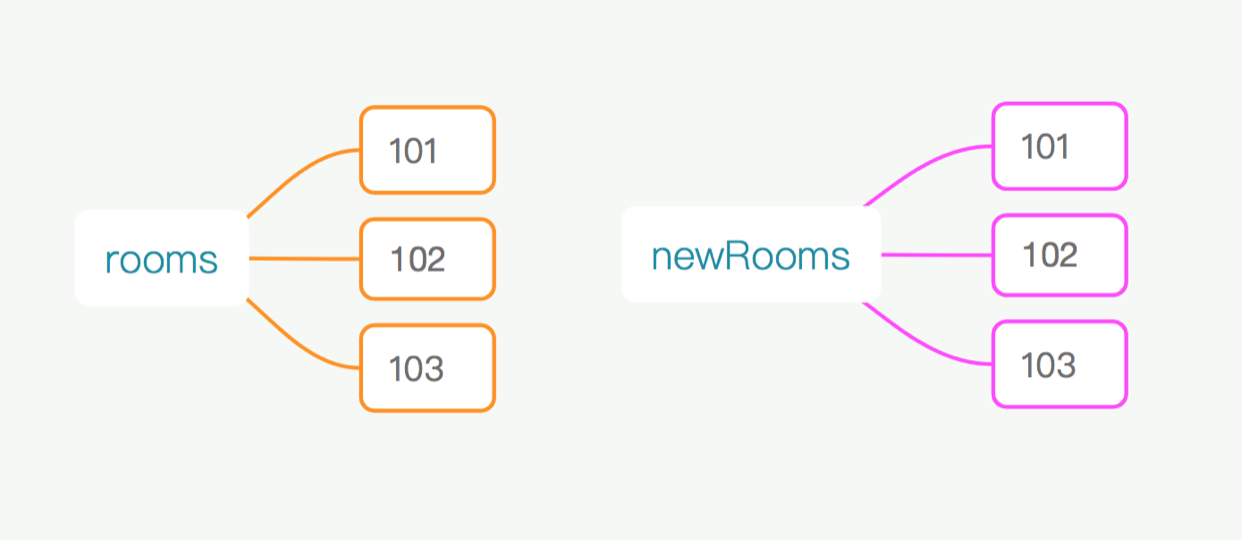
使用不可变数据后,我们复制了一个对象,内存开销翻倍。
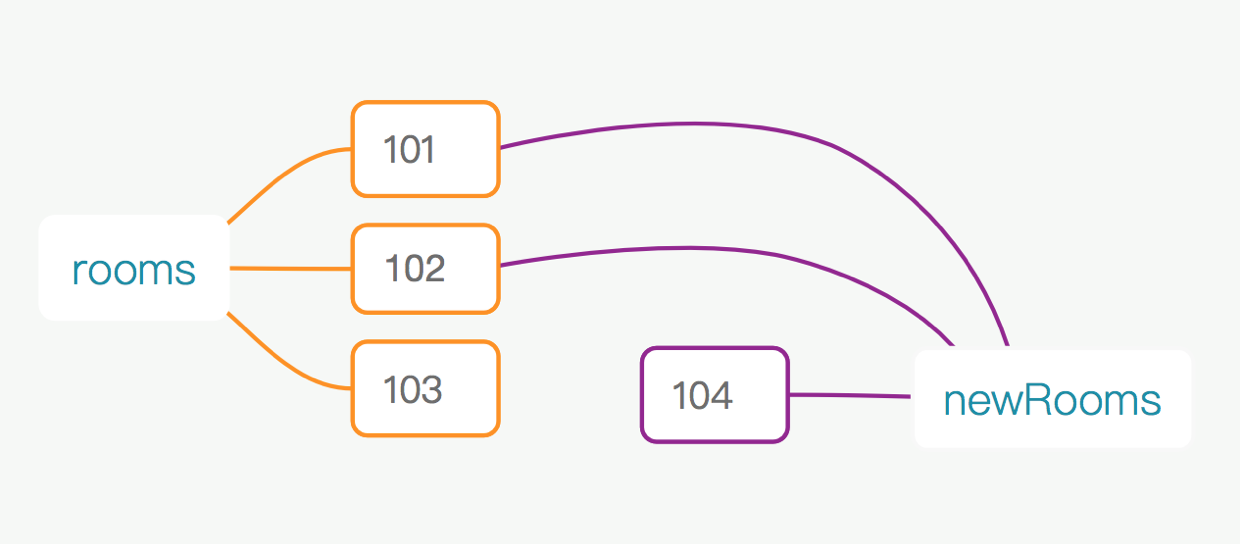
使用 immutableJS 等辅助库后,可以更好地利用之前的数据,优化了内存开销。
闭包 vs 对象
闭包和对象是一样东西的两种表达方式。一个没有闭包的编程语言可以用对象来模拟闭包;一个没有对象的编程语言可以用闭包来模拟对象。两者都可以用来维护数据。
var obj = {
one: 1,
two: 2
};
function run() {
return this.one + this.two;
}
var three = run.bind(obj);
three(); // => 3
function getRun() {
var one = 1;
var two = 2;
return function run(){
return one + two;
};
}
var three = getRun();
three(); // => 3
上面两种方式都可以用来完成程序功能,对象和函数之间可以转换。
常见的辅助函数
unaryreverseArgscurryuncurrycomposepipeasyncPipe
unary,reverseArgs,curry 和 uncurry 是用来进行参数操作的。compose,pipe 和 asyncPipe 是用来进行函数组合的。
unary
unary 是用来限制某个函数只接收一个参数的。常见的使用场景是处理 parseInt 函数:
['1', '2', '3'].map(parseInt);
// => [1, NaN, NaN]
['1', '2', '3'].map(unary(parseInt));
// => [1, 2, 3]
unary 的实现方式可以是:
const unary = (fn) => {
return (arg) => {
return fn(arg);
};
};
reverseArgs
reverseArgs 是用来讲函数参数反转的,实现方式如下:
const reverseArgs = (fn) => {
return (...args) => {
return fn(...args.reverse());
};
};
curry
curry 是用来把函数执行滞后的,让我们可以逐步把参数传入这个函数,当参数完整之后,目标函数才会执行。常见的用法如下:
function add(a, b) {
return a + b;
}
function add10(a) {
return add(10, a);
}
add10(1); // => 11
通过 curry 函数,可以把上面的代码优化一下:
function add(a, b) {
return a + b;
}
const curriedAdd = curry(add);
const add10 = curriedAdd(10);
add10(1); // => 11
curry 的实现思路如下:
把 args,保存起来,每个 curried 函数接受一个参数,将参数拼在之前的参数后面。
const curry = (fn) => {
const curried = (curArg) => {
const args = [...prevArgs, curArg];
return curried;
};
return curried;
};
修改成用闭包保存参数。
const curry = (fn) => {
return (curArg) => {
const args = [...prevArgs, curArg];
return nextCurried(...args);
};
};
递归调用 nextCurried,第一次柯里化的函数不传入参数。
const curry = (fn) => {
const nextCurried = (...prevArgs) => {
return (curArg) => {
const args = [...prevArgs, curArg];
return nextCurried(...args);
};
};
return nextCurried();
};
最后补全 arity 参数,来定义目标函数的参数数量。这样,我们可以定义柯里化后的参数数量,如果传入的参数数量到了函数需要的数量,则直接执行函数,并传入所有的参数。
const curry = (fn, arity = fn.length) => {
const nextCurried = (...prevArgs) => {
return (curArgs) => {
const args = [...prevArgs, curArgs];
if (args.length >= arity) {
return fn(...args);
}
return nextCurried(...args);
};
};
return nextCurried();
};
或者我们可以实现一个支持传入多个参数的柯里化函数:
const curry = (fn, arity = fn.length) => {
const nextCurried = (...prevArgs) => {
return (...curArgs) => {
const args = [...prevArgs, ...curArgs];
if (args.length >= arity) {
return fn(...args);
}
return nextCurried(...args);
};
};
return nextCurried();
};
compose
compose 用来串联执行函数,执行顺序是从后向前的。与之对应的是 pipe 函数,同样是串联执行函数,但是执行顺序是从前向后的。
compose 的用法:
function add10(value) {
return value + 10;
}
function multiple10(value) {
return value * 10;
}
const add10AndMultiple10 = compose(multiple10, add10);
add10AndMultiple10(1); // => 110
compose 的实现:
const compose = (...fns) => {
return fns.reduce((a, b) => {
return (...args) => {
return a(b(...args));
};
});
};
或者通过 reduceRight 简单地从右边向左执行,这是更好理解的一种实现,但是有参数个数的限制。
const compose = (...fns) => {
return (input) => {
return fns.reduceRight((value, fn) => {
return fn(value);
}, input);
};
};
pipe
pipe 也是用来组合函数的,串联执行的顺序是从前向后,与 compose 相反。pipe 的实现可以是:
const pipe = (...fns) => {
return fns.reduceRight((a, b) => {
return (...args) => {
return a(b(...args));
}
});
};
pipe 的用法如下:
const addA = (value) => {
return value + 'A';
};
const addB = (value) => {
return value + 'B';
};
pipe(addA, addB)('1') // => 1AB
asyncPipe
对于异步函数来说,如果我们要串联执行,可以使用 asyncPipe。实现可以是:
const asyncPipe = (...fns) => {
return fns.reduceRight((next, fn) => {
return (...args) => {
fn(...args, next);
};
}, () => {});
};
用法是:
const addA = (value, next) => {
next(value + 'A', 'a');
};
const addB = (value, anotherValue, next) => {
console.log(anotherValue); // => a
next(value + 'B');
};
const consoleLog = (value, next) => {
console.log(value);
};
asyncPipe(addA, addB, consoleLog)('1'); // => 1AB
函数式编程在数据结构上的运用
实现链表
主要思路是用函数闭包代替对象保存数据。
const createNode = (value, next) => {
return (x) => {
if (x) {
return value;
}
return next;
};
};
const getValue = (node) => {
return node(true);
};
const getNext = (node) => {
return node(false);
};
const append = (next, value) => {
if (next === null) {
return createNode(value, null);
}
return createNode(getValue(next), append(getNext(next), value));
};
const reverse = (linkedList) => {
if (linkedList === null) {
return null;
}
return append(reverse(getNext(linkedList)), getValue(linkedList));
};
const linkedList1 = createNode(1, createNode(2, createNode(3, null)));
const linkedList2 = reverse(linkedList1);
getValue(linkedList1); // => 1
getValue(getNext(linkedList1)); // => 2
getValue(getNext(getNext(linkedList1))); // => 3
getValue(linkedList2); // => 3
getValue(getNext(linkedList2)); // => 2
getValue(getNext(getNext(linkedList2))); // => 1
同样可以用函数式编程实现二叉树。
总结
希望大家能够通过学习函数式编程范式,加深对软件研发的理解,开拓视野,找到更多组织代码方式。
函数式编程能够更好地组织业务代码中的数据处理,更多地复用了函数,减少了中间变量。
但是函数式编程也有缺点,它增加了学习成本,需要大家理解高阶函数。